sequenceDiagram
autonumber
actor User
participant Admin Main
participant Admin Server
participant Admin DB
User ->>+ Admin Main: Access Admin Main Page
alt Token exists === true
Admin Main ->>+ Admin Server: Request User Info WIth Token
rect rgba(0, 23, 255, .1)
alt Token valid Ok
Admin Server ->>+ Admin DB : Select User by UserId
Activate Admin DB
rect rgba(0, 56, 255, .1)
alt User exists Ok
Admin DB ->>- Admin Server:Return User Info
Activate Admin Server
Admin Server ->>- Admin Main:Return User Info
Activate Admin Main
Admin Main ->>- User : Data
else User not exists
Admin DB ->>- Admin Server:Return None
Activate Admin Server
Admin Server ->>- Admin Main : Return 404 & Data is None
Activate Admin Main
Admin Main ->>- User : Alert Msg
end
end
else Token Valid False
Admin Server ->>- Admin Main : return 401
Activate Admin Main
Admin Main ->>- User : Token Valid Fail Redirect Admin Sign In
end
end
else Token not Exists
Admin Main ->>- User : Token Not Exists & Redirect Admin Sign In
end
위 프로세스를 토대로 13 개의 요구사항을 정의 해 보았습니다.
이를 토대로 개발에 들어가면 좋을지 고민해 봅니다.
아직은 어설프지만 다이어그램이나 요구사항을 만들어 봤다는 것의 의의를 둡니다.
User 접근에 대한 개발을 하기에 앞서 아무런 User 정보가 없기 때문에 User 정보를 입력받는 Sign Up 과 로그인하는 Sign In 프로세스에 대한 고민을 좀더 해봐야 할 거 같습니다.
from typing import Optional, List
from pydantic import Field, BaseModel
class ResponseModel(BaseModel):
msg:str = Field("", description="응답메세지")
isOk:bool = Field(True, description="응답 성공 여부")
items:Optional[List[dict] | dict] = Field(None, description="응답 데이터")
2. ReponseModelPaging
class Paging(BaseModel):
totalSize: int = Field(0, description="전체 갯수")
totalPage: int = Field(0, description="전체 페이지 수")
page: int = Field(1, description="현재 페이지")
size: int = Field(10, description="출력 갯수")
class ResponseModelPaging(ResponseModel):
paging: Paging = Field(Paging(), description="페이지 정보")
3. Genric Type
from typing import TypeVar, Generic
T = TypeVar("T")
class ResponseModel(BaseModel,Generic[T]):
4. Main
"""
main.py
@제목: 메인 실행 파일
@설명: 메인 실행 파일
작성일자 작성자
-----------------------
2024.03.14 hiio420
"""
import math
import os.path
from fastapi import FastAPI
from pydantic import BaseModel
from starlette.middleware.cors import CORSMiddleware
from libs import ExcelUtils
from models import ResponseModel, ResponseModelPaging, Paging
# 엑셀 파일 불러오기
CUR_DIR = os.path.abspath(os.path.dirname(__file__))
UPLOAD_DIR = os.path.join(CUR_DIR, 'upload')
file_path = os.path.join(UPLOAD_DIR, '(붙임)공공데이터 공통표준용어(2022.7월).xlsx')
excel_utils = ExcelUtils()
df_dict = excel_utils.read_excel(file_path)
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
class Item(BaseModel):
data_id: int = 0
page: int = 1
limit: int = 10
@app.get("/",response_model=ResponseModelPaging[dict])
def read_root(dataId: int = 0, page: int = 1, limit: int = 10, srchTxt: str = ""):
if page < 1:
page = 0
if limit < 10:
limit = 10
df = df_dict[dataId]
df = df[df.apply(lambda row: row.astype(str).str.contains(srchTxt, case=False).any(), axis=1)]
first_idx = (page - 1) * limit
last_idx = first_idx + limit - 1
total_size = df.shape[0]
last_page = math.ceil(total_size / limit)
df_sliced = df[first_idx:last_idx + 1].copy()
df_sliced["번호"] = [i for i in
range(total_size - (page - 1) * limit, total_size - (page - 1) * limit - df_sliced.shape[0], -1)]
data = []
if df_sliced.shape[0] != 0:
data = df_sliced.to_dict("records")
paging = Paging(page=page, size=limit, totalPage=last_page,totalSize=total_size)
resp = ResponseModelPaging(items=data,paging=paging)
print(resp)
return resp
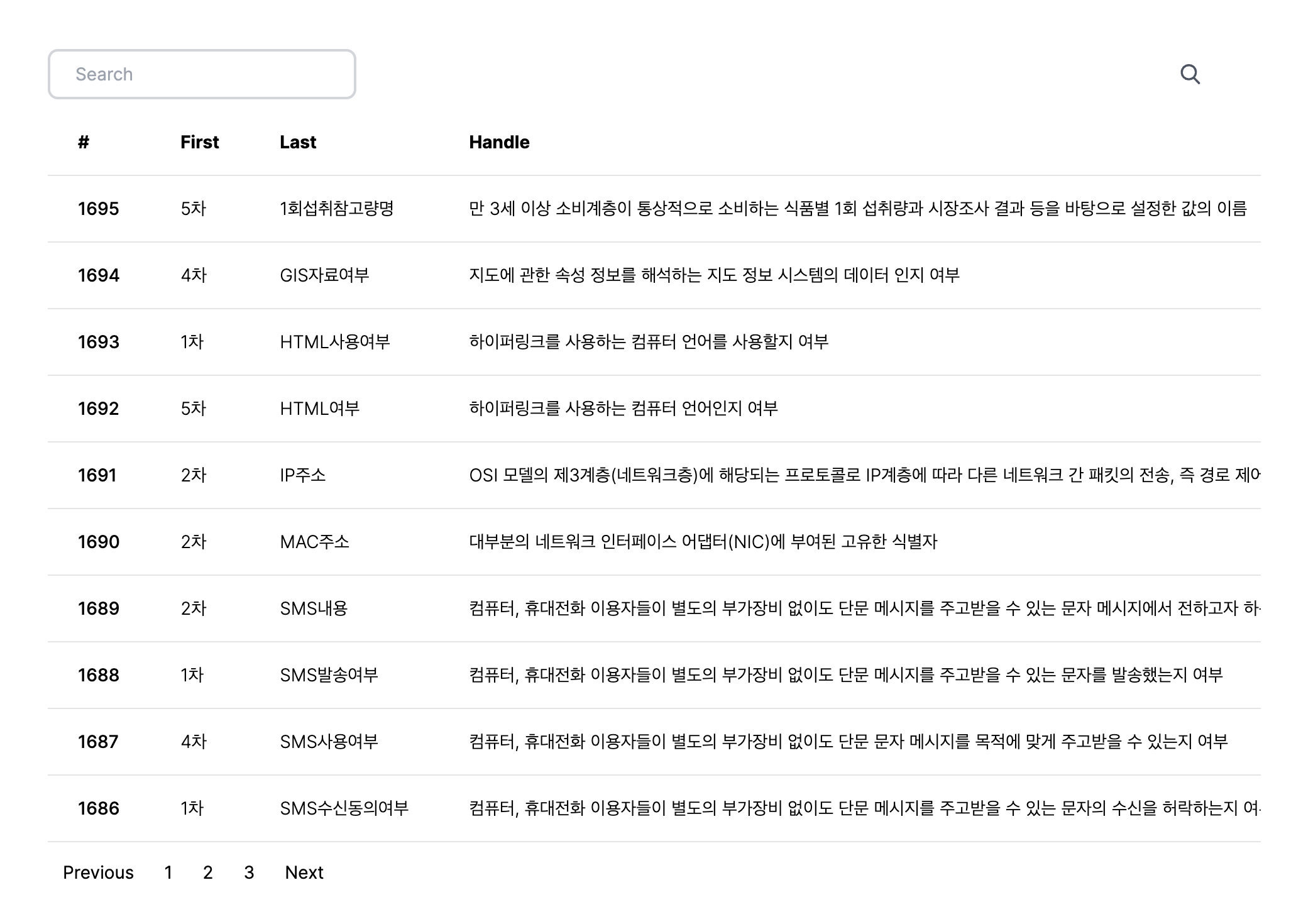
기존에는 공공데이터 포털에서 제공하는 엑셀 파일에서 필요한 부분을 "찾기"를 통해서 검색해서 사용했는데, 이 데이터를 바탕으로 검색을 좀 더 수월하게 하는 웹페이지를 만들면 어떨까 싶기도 하고 최근에는 JAVA와 Oracle로만 프로그래밍을 하다보니 python과 mariaDB에 대한 기억도 가물가물해지는 감도 있어서 작은 개인 프로젝트로서 진행해 보면 어떨까 싶어 시작하게 되었다.
1. 요구사항
이 프로젝트에 필요한 요구사항은 기본적으로 "검색한 단어를 포함하는 공공데이터 공용표준용어의 데이터를 출력"한다는 것이다.